RAID 5 utilizes a
parity function to provide redundancy and data
reconstruction. Typically, an "exclusive OR" ("XOR") binary function is used to
compute parity for a given "row" of the array. Anyway, the parity is computed as
a function of several data blocks P=P(D
1, D
2, ... D
N-1) for N disk layout. In
case of a single drive failure, the inverse function is used to compute data
from the remaining data blocks and parity block.
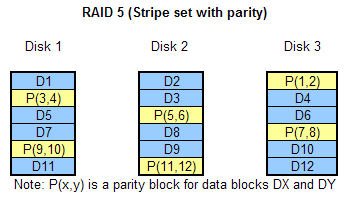
Let's say for example that the Disk 3 fails in configuration illustrated
below.
- Data blocks D1 and D2 will be read directly from their corresponding
disks (which are operational).
- Parity block P1,2 is really not needed (does not contain user data) so
it will be just discarded.
- Data block D3 will be read from its corresponding disk (Disk 2).
- Data block D4, which is missing because its drive is offline will be
reconstructed using D3 and P3,4 like this: D4=Pinverse(D3,P3,4).
During normal operation, read speed gain is (N-1) times, because requests
will be evenly routed to N-1 disks (parity read is not needed during normal
operations). Write procedure is more complicated, and actually imposes some
speed penalty. Let's say we need to write block D1. We also need to update its
corresponding parity block P1,2. There are two ways to accomplish this:
- Read D2; compute P1,2=P(D1,D2); write D1 and P1,2;
- Read D1;old and P1,2;old; compute P1,2
from these data; write D1 and P1,2.
Both of these ways require at least one read operation as the overhead. This
read operation can not be parallelized in any way with its corresponding write
operation, so write speed should decrease (by the factor of two, assuming equal
read and write speed). Most current implementations mitigate this effect by
maintaining the entire "row" (D1, D2 and D3) in
the cache.
Minimum of three disks is required to implement RAID5. Storage space
overhead equals the capacity of a single
member disk and does not depend on the number of disks.
Unlike a RAID0, RAID5 can be recovered with one disk missing; please refer to the RAID5 recovery page for more details.